
كما ذكرنا في الفصل 1 ، محركات البحث هي آلات الإجابة. وهي موجودة لاكتشاف محتوى الإنترنت وفهمه وتنظيمه لتقديم النتائج الأكثر صلة بالأسئلة التي يطرحها الباحثون.
لكي تظهر في نتائج البحث ، يجب أن يكون المحتوى الخاص بك مرئيًا أولاً لمحركات البحث. يمكن القول إنها أهم جزء من أحجية تحسين محركات البحث (SEO): إذا لم يتم العثور على موقعك ، فلن تجد طريقًا إلى SERPs (صفحة نتائج محرك البحث).
كيف تعمل محركات البحث؟
محركات البحث لها ثلاث وظائف أساسية:
- الزحف Crawl: التجول في الإنترنت بحثًا عن المحتوى ، والبحث عن اكواد / محتوى لكل عنوان URL يجدونه.
- الفهرسة Index: يتم تخزين وتنظيم المحتوى الموجود أثناء عملية الزحف. وبمجرد أن تظهر الصفحة في الفهرس ، يتم عرضها مباشرة لعمليات البحث ذات الصلة.
- الترتيب Rank: عرض أجزاء من المحتوى التي من شأنها أن تجيب بشكل أفضل على عملية البحث ، مما يعني أن النتائج مرتبة حسب الأكثر صلة بأقل صلة.
ما هو زحف محرك البحث؟
الزحف هو عملية الاكتشاف التي ترسل فيها محركات البحث فريقًا من الروبوتات (يُعرف باسم برامج الزحف أو العناكب) للعثور على محتوى جديد ومحدث. يمكن أن يختلف المحتوى – قد يكون صفحة ويب أو صورة أو فيديو أو PDF ، إلخ – ولكن بغض النظر عن التنسيق ، يتم اكتشاف المحتوى بواسطة الروابط.
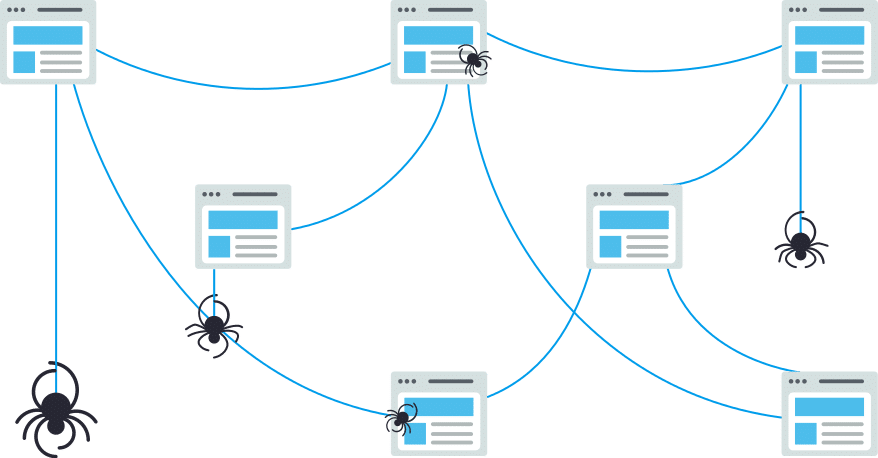
يبدأ Googlebot بجلب بعض صفحات الويب ، ثم يتتبع الروابط الموجودة على صفحات الويب هذه للعثور على عناوين URL جديدة. عن طريق التنقل على طول هذا الطريق من الروابط الموجودة بداخل تلك الصفحات ، بحيث يكون الزاحف قادرًا على العثور على محتوى جديد وإضافته إلى فهرس يسمى Caffeine– وهو عبارة عن قاعدة بيانات ضخمة لعناوين URLs التي تم اكتشافها وفهرستها – ليتم استعادتها لاحقًا في نتائج البحث عندما يبحث شخص ما عن معلومات تتوافق بحد كبير مع المحتوى الموجود على عنواين URL هذه او تتوافق مع عبارات البحث التي يريدها الباحث.
ما هو فهرس محرك البحث؟
تقوم محركات البحث بمعالجة المعلومات التي يعثرون عليها وتخزينها في الفهرس ، وقاعدة البيانات الضخمة التي تحتوي على جميع المحتويات التي اكتشفوها اثناء عملية الزحف والتي تعتبر جيدة بما يكفي لخدمة الباحثين.
ترتيب نتائج محرك البحث
عندما يقوم شخص ما بعملية بحث ، تقوم محركات البحث بفحص فهرسها بحثًا عن محتوى ذو صلة عالية بعبارة البحث المستخدمة ، ثم تعرض ذلك المحتوى للباحث على أمل ان يجيب هذا المحتوي علي عبارة البحث المستخدمة. يُعرف هذا الترتيب لنتائج البحث حسب الصلة بـ ranking. بشكل عام ، يمكنك افتراض أنه كلما تصدر موقع ويب اعلي نتائج البحث كلما كان هذا الموقع اكثر صلة بعبارة البحث المستخدمة حسب مايعتقده خوارزميات محرك البحث.
من الممكن حظر برامج زحف محركات البحث من جزء ما من موقعك أو كل الموقع بشكل عام ، أو منع محركات البحث من تخزين صفحات معينة في فهرسها. بينما قد يكون هناك أسباب للقيام بذلك ، إذا كنت تريد العثور على المحتوى الخاص بك من قبل الباحثين ، عليك أولاً التأكد من أنه يمكن الوصول إليه من قِبل برامج الزحف وقابل للفهرسة. وإلا ، فهي جيدة ولكن ما اهميتها وهي غير مرئية لبرامج البحث او للمستخدمين؟.
بحلول نهاية هذا الفصل ، ستكون قادر علي تحسين محتوي موقعك ليتوافق مع محرك البحث ، وليس ضده!
في السيو، ليست كل محركات البحث متساوية
يتساءل العديد من المبتدئين عن الأهمية النسبية لمحركات البحث الخاصة. يعرف معظم الناس أن Google تمتلك أكبر حصة في السوق ، ولكن ما مدى أهمية تحسين Bing و Yahoo وغيرهم؟ الحقيقة هي أنه على الرغم من وجود أكثر من 30 محرك بحث رئيسي على شبكة الإنترنت ، فإن متخصصين SEO لا يهتمون إلا بـ Google. لماذا؟
الإجابة المختصرة هي أن Google هو المكان الذي تبحث فيه الغالبية العظمى من الناس على الويب. إذا قمنا بتضمين صور Google وخرائط Google و YouTube ، فإن أكثر من 90٪ من عمليات البحث على الويب تحدث على Google – أي ما يقرب من 20 مرة مقارنة بمحرك بحث Bing و Yahoo.
الزحف: هل يمكن لمحركات البحث العثور على موقعك؟
كما تعلمت للتو ، فإن التأكد من الزحف الي موقعك وفهرسته هو شرط أساسي للظهور في نتائج البحث SERPs.
إذا كان لديك موقع ويب بالفعل ، فقد يكون من الضروري أن تبدأ في معرفة عدد صفحاتك الموجودة في الفهرس. سيساعدك ذلك في الحصول على بعض الأفكار المهمة حول ما إذا كانت Google تقوم بالزحف والبحث عن جميع الصفحات المهمة في موقعك والتي تريد تضمينها بنتائج البحث ، وليس أي شيء اخر غير مهم.
إحدى طرق التحقق من صفحاتك المفهرسة هي “site:yourdomain.com” ، وهو مشغل بحث متقدم Search Operator.
توجه إلى Google واكتب “site:yourdomain.com” في شريط البحث واستبدل yourdomain.com برابط موقعك. سيعرض هذا الامر الروابط التي تم فهرستها علي محرك بحث Google:
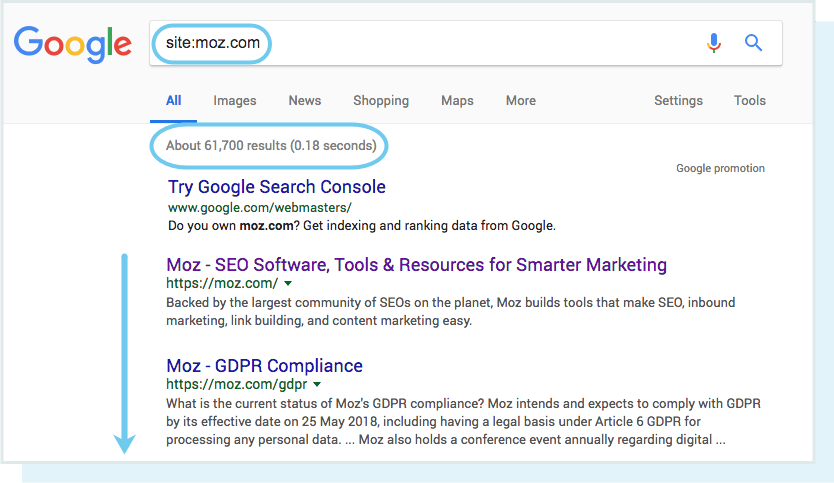
عدد الصفحات التي تم فهرستها علي Google هو 61,700 صفحة ، هذا الرقم ليس بالتحديد ولكنه يمنحك فكرة تقريبية عن عدد الصفحات التي تم فهرستها من موقعك وكيف يتم عرضها حاليًا في نتائج البحث.
للحصول على نتائج أكثر دقة ، راقب واستخدم تقرير تغطية الفهرس في Google Search Console.
يمكنك الاشتراك للحصول على حساب مجاني على Google Search Console إذا لم يكن لديك حساب حاليًا. باستخدام هذه الأداة ، يمكنك إرسال ملفات Sitemap لموقعك ومراقبة عدد الصفحات المرسلة التي تمت إضافتها بالفعل إلى فهرس Google ، والعديد من الاشياء الاخرى.
إذا كان موقعك لايظهر في نتائج البحث ، فهناك بعض الأسباب المحتملة لما يلي:
- موقعك جديد ولكن لم يتم الزحف إليه بعد.
- موقعك جديد ولايحصل علي اي روابط خلفية باك لينك من اي مواقع اخري.
- يجعل التنقل في موقعك من الصعب على الروبوت الزحف إليه بفعالية.
- يحتوي موقعك على بعض الاكواد البرمجية الأساسية التي تحظر عناكب محركات البحث من الدخوال اليه وفهرسته.
- تمت معاقبة موقعك من قِبل Google بسبب تكتيكات الاسبام “Spam”.
أخبر محركات البحث عن كيفية الزحف إلى موقعك
إذا استخدمت Google Search Console أو “site:domain.com” advanced search operator ووجدت أن بعض صفحاتك المهمة مفقودة من الفهرس و / أو تمت فهرسة بعض صفحاتك غير المهمة ، فهناك بعض التحسينات التي يمكنك تنفيذها لتوجيه Googlebot بشكل أفضل لكيف تريد الزحف الي محتوى الويب الخاص بك. حيث ان إخبار محركات البحث بكيفية الزحف إلى موقعك يمكن أن يمنحك سيطرة أفضل على ما يعرض في فهرس جوجل.
يفكر معظم الأشخاص في التأكد من قدرة Google على العثور على صفحاتهم المهمة ، ولكن من السهل أن تنسى أن هناك صفحات محتملة لا تريد أن يجدها Googlebot. قد تتضمن هذه أشياء مثل عناوين URL القديمة التي تحتوي على محتوى رفيع ، وعناوين URL مكررة (مثل معلمات الفرز والتصفية للتجارة الإلكترونية) ، وصفحات شفرة الترويجي الخاصة ، وصفحات التدريج أو الاختبار ، وما إلى ذلك.
لتوجيه Googlebot بعيدًا عن صفحات وأقسام معينة من موقعك ، استخدم ملف robots.txt.
ملف robots.txt
توجد ملفات Robots.txt في الدليل الجذري لمواقع الويب (على سبيل المثال ، yourdomain.com/robots.txt) وتخبر محركات البحث بالاجزاء التي يجب الزحف اليها في موقعك والتي لا يجب الزحف إليها ، وكذلك السرعة التي يزحفون بها إلى موقعك.
كيف يتعامل Googlebot مع ملفات robots.txt
- إذا تعذر على Googlebot العثور على ملف robots.txt لأحد المواقع ، فسيتم الانتقال إلى الزحف إلى الموقع.
- إذا عثر Googlebot على ملف robots.txt لأحد المواقع ، فسوف يلتزم عادة بالاقتراحات ويستمر في الزحف إلى الموقع.
- إذا واجه برنامج Googlebot خطأً أثناء محاولة الوصول إلى ملف robots.txt لأحد المواقع ولا يمكنه تحديد ما إذا كان أحده موجودًا أم لا ، فلن يزحف إلى الموقع.
تكلفة الزحف Crawl Budget
ميزانية او تكلفة الزحف هي متوسط عدد عناوين URL التي سيقوم برنامج Googlebot بالزحف إليها على موقعك قبل مغادرته ، وبالتالي تضمن ميزانية تحسين الزحف أن برنامج Googlebot لا يضيع الوقت في الزحف عبر صفحاتك غير المهمة المعرضة لخطر تجاهل صفحاتك المهمة. تعد ميزانية الزحف أكثر أهمية في المواقع الكبيرة جدًا التي تحتوي على عشرات الآلاف من عناوين الروابط URL ، ولكن ليس من الجيد أبدًا منع الزواحف من الوصول إلى المحتوى الذي لا يهمك بالتأكيد. فقط تأكد من عدم حظر وصول الزاحف إلى الصفحات التي تحتوي علي توجيهات برامج الزحف ، عن طريق اضافة canonical او noindex tags. حيث انه إذا تم حظر Googlebot من إحدى الصفحات التي بداخلها تلك الارشادات الموجهه لبرامج الزحف ، فلن تتمكن تلك البرامج من رؤية الإرشادات الموجودة على هذه الصفحات.
لاتتبع كل روبوتات الويب ملف robots.txt. حيث ينشئ الأشخاص ذوو النوايا السيئة بعض برامج الروبوت التي لا تتبع هذا البروتوكول. في الواقع ، يستخدم بعض الهاكرز ملفات robots.txt للعثور على المكان الذي توجد فيه محتويات موقعك المهمة القابلة للسرقة. على الرغم من أنه قد يكون من المنطقي حظر برامج الزحف من الصفحات الخاصة مثل صفحات تسجيل الدخول والإدارة admin حتى لا تظهر في الفهرس ، فإن وضع عناوين URL هذه الصفحات المهمة في ملف robots.txt يُمكن عناكب البحث من الوصول إليه بشكل عام مما يعني أيضًا أن الأشخاص ذوي النوايا الخبيثة يمكنهم العثور علي هذه الصفحات بسهولة. لذا من الأفضل وضع علامة NoIndex علي هذه الصفحات واخفائها خلف نموذج تسجيل الدخول بدلاً من وضعها في ملف robots.txt الخاص بك.
تحديد معلمات URL في GSC
تتيح بعض المواقع (الأكثر شيوعًا في مواقع التجارة الإلكترونية) نفس المحتوى على عناوين URL مختلفة متعددة عن طريق إلحاق معلمات معينة parameters بعناوين URL. إذا كنت قد قمت بالتسوق عبر الإنترنت ، فمن المحتمل أن تقوم بتضييق نطاق البحث داخل المتاجر عبر الفلاتر. على سبيل المثال ، يمكنك البحث عن “أحذية” على Amazon ، ثم تخصيص البحث حسب المقاس واللون. في كل مرة تقوم فيها بالتخصيص ، يتغير عنوان URL قليلاً لصيبح مثل هذا الشكل:
https://www.example.com/products/women/dresses/green.htm https://www.example.com/products/women?category=dresses&color=green https://example.com/shopindex.php?product_id=32&highlight=green+dress &cat_id=1&sessionid=123$affid=43
كيف تعرف Google أي نسخة من عنوان URL تخدم الباحثين؟ تقوم Google بعمل جيد جدًا في معرفة عنوان URL التمثيلي “representative URL” بمفردها ، ولكن يمكنك استخدام ميزة معلمات URL في Google Search Console لإخبار Google بالطريقة التي تريدها أن تتعامل بها مع صفحاتك. إذا كنت تستخدم هذه الميزة لإخبار Googlebot “عدم الزحف إلى عناوين URL باستخدام المعلمة __” ، فأنت تطلب أساسًا إخفاء هذا المحتوى من Googlebot ، مما قد يؤدي إلى إزالة هذه الصفحات من نتائج البحث. هذا ما تريده إذا أنشأت هذه المعلمات صفحات مكررة ، ولكنها ليست مثالية إذا كنت تريد فهرسة تلك الصفحات.
الآن بعد أن عرفت بعض الأساليب لضمان بقاء برامج زحف محركات البحث بعيدًا عن المحتوى غير المهم ، دعنا نتعرف على التحسينات التي يمكن أن تساعد Googlebot في العثور على صفحاتك المهمة.
هل تستطيع برامج الزحف العثور على جميع الصفحات المهمة علي موقعك؟
في بعض الأحيان ، يكون محرك البحث قادرًا على العثور على أجزاء من موقعك عن طريق الزحف ، ولكن قد يتم حجب الصفحات أو الأقسام الأخرى لسبب أو لآخر. من المهم التأكد من أن محركات البحث قادرة على اكتشاف كل المحتوى الذي تريد فهرسته ، وليس فقط صفحتك الرئيسية.
اسأل نفسك هذا السؤال: هل يمكن لعناكب الزحف الزحف داخل موقع الويب الخاص بك ، وليس فقط لذلك الرابط بالتحديد؟

هل المحتوى الخاص بك مخفي وراء نماذج تسجيل الدخول؟
إذا طلبت من المستخدمين تسجيل الدخول أو ملء النماذج أو الرد على الاستطلاعات قبل الوصول إلى محتوى معين ، فلن ترى محركات البحث تلك الصفحات المحمية. بالتأكيد لن يقوم الزاحف بتسجيل الدخول
هل تعتمد على نماذج البحث؟
لا يمكن للروبوتات استخدام نماذج البحث. يعتقد بعض الأفراد أنهم إذا وضعوا مربع بحث على موقعهم ، فستتمكن محركات البحث من العثور على كل شيء يبحث عنه زوارهم.
هل النص مخفي داخل محتوى غير نصي؟
يجب عدم استخدام نماذج الوسائط غير النصية (الصور ، الفيديو ، صور GIF ، وما إلى ذلك) لعرض نص ترغب في فهرسته. بينما تتحسن محركات البحث في التعرف على الصور ، ليس هناك ما يضمن أنها ستكون قادرة على قراءتها وفهمها حتى الآن. من الأفضل دائمًا إضافة نص داخل علامة <HTML> لصفحة الويب الخاصة بك.
هل يمكن لمحركات البحث متابعة التنقل في موقعك؟
تمامًا كما يحتاج الزاحف إلى اكتشاف موقعك عبر روابط من مواقع أخرى ، فإنه يحتاج إلى مسار من الروابط على موقعك لتوجيهه من صفحة إلى أخرى “ونحن نتحدث هنا عن اهمية ربط مقالات موقعك الداخلية ببعضها”. إذا كان لديك صفحة علي موقعك وتريد ان تعثر عليها محركات البحث ولكنها غير مرتبطة بأي من الصفحات الأخرى داخل موقعك ، فهي جيدة إلى حد غير مرئي. ترتكب العديد من المواقع خطأ فادحًا في هيكلة التنقل بالطرق التي يتعذر على محركات البحث الوصول إليها ، مما يعيق قدرتها على الظهور في نتائج البحث.
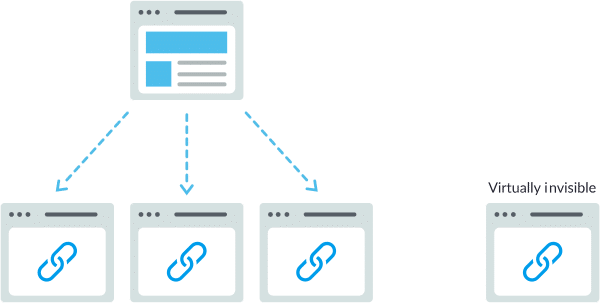
أخطاء التنقل الشائعة التي يمكن أن تمنع برامج الزحف من رؤية موقعك بالكامل:
- امتلاك ميزة التنقل عبر الأجهزة المحمولة والتي تعرض نتائج مختلفة عن التنقل على سطح المكتب
- أي نوع من التنقل يكون فيه عناصر القائمة يستدخم اكواد غير HTML ، مثل التنقلات التي تدعم JavaScript. لقد تحسنت Google كثيرًا في الزحف إلى جافا سكريبت وفهمها ، لكنها لا تزال ليست عملية مثالية. لضمان العثور على شيء وفهمه وفهرسته بواسطة Google عليك وضعه بداخل اكواد HTML.
- قد يبدو التخصيص Personalization ، أو إظهار التنقل الفريد لنوع معين من الزائرين الذين يزورون موقعك ، وكأنه يتستر علي زاحف محرك بحث
- ننسى الاشارة للصفحات الأساسية على موقع الويب الخاص بك – تذكر أن الروابط هي المسارات التي تتبعها برامج الزحف للوصول إلى الصفحات الجديدة!
هذا هو السبب في أنه من الضروري أن يحتوي موقع الويب الخاص بك على بنية مجلدات URL مفيدة ومناسبة للتنقل.
هل لديك بنية معلومات information architecture منظمة؟
بنية المعلومات هي ممارسة مهمة لتنظيم وتسمية المحتوى على موقع ويب لتحسين إمكانية الوصول لروابط محتوي موقعك للمستخدمين. كما تعتبر بنية المعلومات المنظمة شئ اساسي لابد من تواجده في الموقع ، مما يعني أنه لا ينبغي أن يفكر المستخدمون لوقت طويل لكي يتنقلوا عبر موقع الويب الخاص بك للعثور على شيء ما.
هل تستخدم ملفات Sitemap؟
خريطة الموقع هي ما يبدو عليه تمامًا موقعك: قائمة عناوين URL على موقعك والتي يمكن أن تستخدمها برامج الزحف لاكتشاف المحتوى الخاص بك وفهرسته. واحدة من أسهل الطرق لضمان قيام Google بالعثور على صفحات موقعك المهمة هي إنشاء ملف يفي بمعايير Google وإرساله عبر وحدة تحكم بحث Google. أثناء تقديم ملف Sitemap ليس من الضروري ان تحتاج الي تصفح توجيه مثالي لمحتوي وروابط الموقع ، حيث ان ملف خريطة الموقع يمكن أن يساعد برامج الزحف بالتأكيد على الوصول إلى جميع صفحاتك المهمة.
تأكد من أنك قمت فقط بتضمين عناوين URL التي تريد فهرستها بواسطة محركات البحث ، وتأكد من إعطاء برامج الزحف اتجاهات ثابتة. على سبيل المثال ، لا تقم بتضمين عنوان URL في ملف Sitemap الخاص بك والذي سبق وإن قمت بحظره من خلال ملف robots.txt أو ان تقوم بتضمين عناوين URL في ملف Sitemap التي هي مكررة او النسخة نفسها بشكل مختلف “canonical version” (سنقدم مزيدًا من المعلومات حول هذه الامور في الفصل 5!).
إذا كان موقعك لا يحصل علي اي روابط خلفية ، فلا يزال بإمكانك محاولة ارشفة موقعك عن طريق إرسال خريطة الموقع XML في Google Search Console. ليس هناك ما يضمن إدراجهم لعنواين موقعك URL في فهرسهم ، لكن الأمر يستحق المحاولة ويجدي نفعاً اغلب الاوقات!
هل تحصل برامج الزحف على أخطاء عند محاولة الوصول إلى عناوين URL الخاصة بك؟
في عملية الزحف إلى عناوين URL على موقعك ، قد يواجه الزاحف أخطاء. يمكنك الانتقال إلى تقرير “أخطاء الزحف” في Google Search Console للكشف عن عناوين URL التي قد تسبب ذلك – يعرض لك هذا التقرير أخطاء في الخادم server errors والملفات الغير موجودوة not found errors. يمكن أن تعرض لك ملفات سجل الخادم server log files هذا أيضًا ، بالإضافة إلى مجموعة من المعلومات الأخرى مثل تردد الزحف crawl frequency ، ولكن نظرًا لأن الوصول إلى ملفات سجل الخادم والتعامل معاها يعد أمراً أكثر تقدمًا ، فلن نناقشه بالتفصيل في هذا الديل ، على الرغم من أنه يمكنك معرفة المزيد عنها هنا.
قبل أن تتمكن من فعل أي شيء في تقرير أخطاء الزحف crawl error ، من المهم أن تفهم أخطاء الخادم والأخطاء “الغير موجودة”.
4xx Codes: عندما يتعذر على برامج زحف محركات البحث الوصول إلى المحتوى الخاص بك بسبب خطأ مع المستخدم
أخطاء 4xx هي أخطاء شائعة تظهر للمستخدمين وبرامج الزحف ، مما يعني أن عنوان URL المطلوب يحتوي على بناء جملة غير صحيح أو لا يمكن الوصول اليه. أحد أكثر أخطاء 4xx شيوعًا هو الخطأ “404 – غير موجود”. قد تحدث هذه بسبب خطأ املائي في كتابة الرابط أو ان الصفحة التي يبحث عنها المستخدم محذوفة أو ان عملية إعادة توجيه الرابط لا تتم بشكل سليم ، وذلك على سبيل المثال لا الحصر. عندما تصل محركات البحث إلى الروابط الغير موجودة 404 ، لا يمكنهم الوصول إلى عنوان URL هذا. وعندما يصل المستخدمون إلى هذه الروابط الغير موجودة 404 ، لن يجدوا شيئاً ومن المحتمل انهم سيغادرون الموقع علي الفور .
5xx Codes: عندما يتعذر على برامج زحف محركات البحث الوصول إلى المحتوى الخاص بك بسبب خطأ في الخادم
أخطاء 5xx هي أخطاء تحدث بسبب الخادم ، مما يعني انها اخطاء تحدث بسبب فشل في الخادم نفسه مما يتعذر علي الخادم عرض صفحة الويب لتلبية طلب الباحث أو محرك البحث واعاقة الوصول إلى الصفحة المطلوبة. في تقرير “خطأ الزحف” في Google Search Console ، هناك علامة تبويب مخصصة لهذه الأخطاء. ويحدث هذا النوع من الاخطاء عادةً بسبب انتهاء مهلة طلب عنوان URL ، لذلك يهمل Googlebot هذه الروابط. اقرأ وثائق Google لمعرفة المزيد حول إصلاح مشكلات اتصال الخادم.
لحسن الحظ ، هناك طريقة لإخبار كل من الباحثين ومحركات البحث بأن صفحتك المعطلة قد انتقلت لصفحة جديدة تعمل – وذلك عبر إعادة التوجيه الدائمة 301.
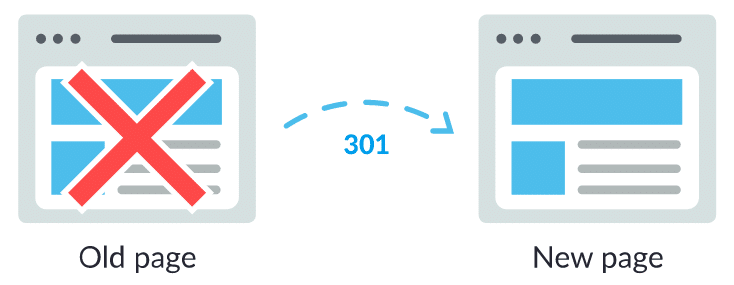
لنفترض أنك قمت بنقل صفحة من example.com/young-dogs/ إلى example.com/puppies/. تحتاج محركات البحث والمستخدمون إلى جسر للعبور من عنوان URL القديم إلى الجديد. هذا الجسر هو إعادة التوجيه 301.
| عند تنفيذ 301: | عندما لا تنفذ 301: | |
| Link Equity | نقل ملكية الرابط من الموقع القديم للصفحة إلى عنوان URL الجديد. | بدون اعادة توجيه 301 ، لا يتم تمرير اثورتي الصفحة من عنوان URL السابق إلى الإصدار الجديد من عنوان URL. |
| Indexing | يساعد Google في العثور على الإصدار الجديد من الصفحة وفهرسته. | إن وجود 404 أخطاء على موقعك وحده لا يضر بأداء البحث ، ولكن ترك التصنيفات / الصفحات الغير موجودة 404 يمكن أن يؤدي إلى سقوطها في الفهرس ، مع فقدان الترتيب والترافيك الذي يأتي منها |
| User Experience | يضمن للمستخدمين العثور على الصفحة التي يبحثون عنها. | سيؤدي السماح للزائرين بالنقر فوق الروابط المفقودة إلى نقلهم إلى صفحات الأخطاء بدلاً من الصفحة المقصودة ، والتي قد تكون محبطة. |
تشير اعادة التوجيه 301 نفسها إلى أن الصفحة قد انتقلت نهائيًا إلى موقع جديد ، لذا تجنب إعادة توجيه عناوين URL إلى الصفحات غير ذات الصلة – عناوين URL التي لاينتمي المحتوي القديم فعليا لها. إذا كانت إحدى الصفحات تاخذ ترتيب في نتائج البحث علي عبارة بحث معينة وقمت بتحويلها بشكل دائم 301 إلى عنوان URL بمحتوى مختلف عن ذي قبل ، فقد تنخفض في موضع الترتيب لأن المحتوى الذي جعلها ذات صلة بعبارة البحث هذه لم يعد موجودًا الان.
301s ذات مفعول قوي – ولكن انقل عناوين URL بحذر!
لديك أيضًا خيار 302 لإعادة توجيه الصفحة ، ولكن يجب أن يكون ذلك مخصصًا للتنقلات المؤقتة وفي الحالات التي لا يكون فيها نقل قوة الرابط link equity كبيرًا. 302s هي نوع من انواع عمليات اعادة التوجية الذي يمكن تشبيه باختصارات الطرق المؤقتة. أنت تقوم مؤقتًا بتحويل حركة المرور عبر مسار معين ، ولكن ذلك لن يكون هكذا إلى الأبد انه حل مؤقت فقط.
احترس من حلقات إعادة التوجيه redirect chains!
قد يكون من الصعب على Googlebot الوصول إلى صفحتك إذا كان يتعين عليها إجراء عمليات إعادة توجيه متعددة. يطلق Google على هذه “سلاسل إعادة التوجيه” ويوصون بتقليلها قدر الإمكان. إذا قمت بإعادة توجيه example.com/1 إلى example.com/2 ، فحينئذٍ قررت إعادة توجيهه إلى example.com/3 ، فمن الأفضل التخلص من الوسيط وإعادة توجيه example.com/1 إلى example.com/3 مباشرو بدون وسيط بين الصفحتين.
بمجرد التأكد من تحسين موقعك لكي يكون قابل الزحف ، الامر التالي هو التأكد من إمكانية فهرسته”قابل للفهرسه”.
الفهرسة: كيف تقرأ محركات البحث صفحاتك وتخزنها؟
بمجرد التأكد من أن موقعك قد تم الزحف إليه ، فإن الجزء التالي من العمل هو التأكد من إمكانية فهرسته. هذا صحيح – ليس لمجرد أنه يمكن اكتشاف موقعك والزحف إليه بواسطة محرك بحث انه يعني بالضرورة أنه سيتم تخزينه في فهرسه. في القسم السابق الخاص بالزحف ، ناقشنا كيفية اكتشاف محركات البحث لصفحات الويب الخاصة بك. الفهرس هو المكان الذي يتم فيه تخزين صفحاتك المكتشفة. بعد أن يعثر الزاحف على هذه الصفحات ، يعرضها محرك البحث تمامًا كما يفعل المتصفح. أثناء القيام بذلك ، يحلل محرك البحث محتويات تلك الصفحة. ويتم تخزين كل هذه المعلومات في فهرسها في المكان المناسب لهذا المحتوي.

تابع القراءة لتتعرف على كيفية عمل الفهرسة وكيف يمكنك التأكد من أن موقعك يعمل بشكل جيد في قاعدة البيانات المهمة للغاية.
هل يمكنني رؤية كيف يرى زاحف Googlebot صفحاتي؟
نعم ، سيعكس الإصدار المخزن لصفحتك cached version لقطة من آخر مرة قام برنامج Googlebot بالزحف إليها.
يقوم Google بالزحف إلى صفحات الويب وتخزينها مؤقتًا بناء علي على عوامل مختلفة. حيث سيتم الزحف الي المواقع الأكثر شهرة والتي تنشر اخبار بشكل متكرر ومنتظم مثل https://www.nytimes.com أكثر من المواقع الأقل شهرةً او المواقع الجديدة ، http://www.rogerlovescupcakes.com ( لو كانموقع موجود من الاساس …)
يمكنك عرض شكل النسخة المخزنة من خلال النقر على السهم المنسدل بجوار عنوان URL في SERP واختيار “Cached”:
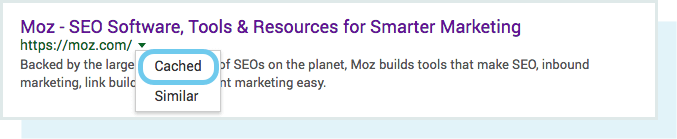
يمكنك أيضًا عرض النسخة النصية فقط من موقعك لتتأكد من ما إذا كان المحتوى المهم الخاص بك يتم الزحف إليه وتخزينه مؤقتًا بشكل فعال ام لا.
هل يمكن ان تقوم محركات البحث بإزالة الصفحات من الفهرس؟
نعم ، يمكن إزالة الصفحات من الفهرس! واليك بعض الأسباب الرئيسية وراء إزالة عنوان URL من الفهرس:
- يُظهر عنوان URL خطأ “غير موجود” (4XX) أو خطأ في الخادم (5XX) – هذا الامر وراد الحدوث حيث قد (يتم نقل الصفحة ولكن لم يتم إعداد إعادة توجيه 301) أو ان يحدث الامر بقصد (لكي يتم حذف الصفحة وتصبح غير موجودة 404 بهدف ان يتم إزالتها من الفهرس)
- تمت إضافة تاج او علامة noindex لعنوان URL – يمكن إضافة هذه العلامة بواسطة مالك الموقع لإخبار محرك البحث بحذف الصفحة من فهرسها.
- تمت معاقبة عنوان URL يدويًا لمخالفته إرشادات مشرفي المواقع الخاصة بمحرك البحث ، ونتيجة لذلك ، تمت إزالته من الفهرس.
- تم حظر URL من الزحف مع إضافة كلمة مرور مطلوبة قبل أن يتمكن الزوار من الوصول إلى الصفحة.
إذا كنت تعتقد أن صفحة على موقع الويب الخاص بك كانت موجودة سابقًا في فهرس Google لم تعد معروضة ، فيمكنك استخدام أداة فحص عناوين URL لمعرفة حالة الصفحة ، أو استخدام Fetch As Google الذي يحتوي على ميزة “طلب فهرسة” وإرسال عناوين URL الفردية إلى الفهرس. (المكافأة: تحتوي أداة “الجلب” من GSC’s أيضًا على خيار “render” يتيح لك معرفة ما إذا كانت هناك أية مشكلات في كيفية رؤية Google لصفحتك).
أخبر محركات البحث عن كيفية فهرسة موقعك
“Robots meta directives “Tags
روبوتس ميتا تاجز Robots meta tags هي إرشادات يمكنك إعطاءها لمحركات البحث فيما يتعلق بكيفية معالجة صفحة الويب الخاصة بك.
يمكنك إخبار زواحف محركات البحث بأشياء مثل “لا تقم بفهرسة هذه الصفحة في نتائج البحث” أو “لا تقم بتتبع أي روابط في هذه الصفحة”. يتم تنفيذ هذه التعليمات عبر Robots Meta Tags في رأس <head> صفحات HTML (الأكثر استخدامًا) أو عبر X-Robots-Tag في HTTP header.
Robots meta tag
يمكن استخدام robots meta tag في رأس <head> صفحة HTML لصفحة الويب الخاصة بك. يمكن أن يستبعد كل أو بعض محركات البحث المحددة. فيما يلي meta directives الأكثر شيوعًا ، بالتفصيل مع المواقف التي قد تُطبق فيها.
index / noindex يخبر محركات البحث بما إذا كان يجب الزحف إلى الصفحة والاحتفاظ بها في فهرس محركات البحث لاستعادتها مره اخري ام لا. إذا اخترت استخدام “noindex” ، فأنت تخبر برامج الزحف بأنك تريد استبعاد الصفحة من نتائج البحث. بشكل افتراضي ، محركات البحث تستطيع فهرسة جميع الصفحات افتراضياً ، لذا فإن استخدام قيمة “index” غير ضروري بالمره.
متي يمكن استخدامه: يمكنك اختيار وضع علامة على الصفحة على أنها “noindex” إذا كنت تحاول تقليم الصفحات الرفيعة من فهرس Google لموقعك (على سبيل المثال: صفحات الملف الشخصي التي أنشأها المستخدمون) ولكنك لا تزال تريد وصول الزوار إليها.
follow / nofollow محركات البحث ما إذا كان يجب اتباع الروابط الموجودة على الصفحة أم لا. ينتج عن “متابعة” روبوتات تتبع الروابط على صفحتك وتمرير ملكية الرابط إلى عناوين URL هذه. أو ، إذا اخترت استخدام “nofollow” ، فلن تتبع محركات البحث أو تنقل أي ملكية للرابط إلى الروابط الموجودة على الصفحة. افتراضيًا ، يُفترض أن تحتوي جميع الصفحات على السمة “متابعة”.
متي يمكن استخدامهم: غالبًا ما يستخدم nofollow مع noindex عندما تحاول منع فهرسة صفحة وكذلك منع الزاحف من اتباع الروابط الموجودة فى هذه الصفحة.
يستخدم noarchive لتقييد محركات البحث من حفظ نسخة مخزنة من الصفحة cached copy. بشكل افتراضي ، ستحتفظ المحركات بنسخ مرئية من جميع الصفحات التي فهرستها ، ويمكن للباحثين الوصول إليها من خلال الرابط المخزن cached link في نتائج البحث.
متي يمكن استخدامها: إذا كنت تدير موقعًا للتجارة الإلكترونية e-commerce site وتغير أسعارك بانتظام ، فقد تفكر في وضع علامة noarchive لمنع الباحثين من رؤية الأسعار القديمة.
إليك مثال على برامج الروبوت meta robots noindex, nofollow tag:
<!DOCTYPE html>
<html>
<head>
<meta name="robots" content="noindex, nofollow" />
</head>
<body>...</body>
</html>يستثني هذا المثال جميع محركات البحث من فهرسة الصفحة ومن تتبع أي روابط على الصفحة. إذا كنت تريد استبعاد عدة برامج زحف ، مثل googlebot و bing على سبيل المثال ، فلا بأس في استخدام علامات استبعاد الروبوت المتعددة multiple robot exclusion tags.
تؤثر توجيهات التعريف على الفهرسة ، وليس الزحف
يحتاج Googlebot إلى الزحف إلى صفحتك من أجل الاطلاع على توجيهات التعريف الخاصة به ، لذلك إذا كنت تحاول منع برامج الزحف من الوصول إلى صفحات معينة ، فإن توجيهات التعريف ليست هي الطريقة للقيام بذلك. يجب أن يتم الزحف إلى علامات الروبوت حتى يتم احترامها.
X-Robots-Tag
يتم استخدام علامة x-robots في هيدر HTTP لعنوان URL الخاص بك ، مما يوفر مرونة ووظائف أكثر من العلامات الوصفية meta tags إذا كنت تريد حظر محركات البحث على نطاق واسع لأنه يمكنك استخدام تعبيرات عادية وحظر ملفات غير HTML وتطبيق علامات علي مستوي الموقع noindex .
على سبيل المثال ، يمكنك بسهولة استبعاد مجلدات بأكملها أو أنواع ملفات بالكامل (مثل moz.com/no-bake/old-recipes-to-noindex):
<Files ~ “\/?no\-bake\/.*”>
Header set X-Robots-Tag “noindex, nofollow”
</Files>أو أنواع ملفات محددة (مثل ملفات PDF):
<Files ~ “\.pdf$”>
Header set X-Robots-Tag “noindex, nofollow”
</Files>لمزيد من المعلومات حول علامات Meta Robot ، اقرأ مواصفات علامة Meta Robot الخاصة بـ Google.
نصيحة لمستخدمي ووردبريس:
في Dashboard > Settings > Reading ، تأكد من عدم تحديد مربع “Search Engine Visibility”. حيث ان هذا يمنع محركات البحث من الوصول إلى موقعك عبر ملف robots.txt الخاص بك!
سيساعدك فهم الطرق المختلفة التي يمكنك من خلالها التأثير على الزحف والفهرسة من تجنب المشاكل الشائعة التي يمكن أن تمنع برامج الزحف من العثور على صفحاتك المهمة.
الترتيب Ranking: كيف ترتب محركات البحث عناوين URL؟
كيف تضمن محركات البحث أنه عندما يقوم شخص ما بكتابة كلمة مفتاحية في شريط البحث ، فإنه يحصل على النتائج ذات الصلة في المقابل؟ تُعرف هذه العملية باسم الترتيب ، أو ترتيب نتائج البحث حسب الأكثر صلةً بأقل صلة حسب كلمة او عبارة البحث.

لتحديد مدى تطابق النتائج relevance مع عبارات البحث queries ، تستخدم محركات البحث الخوارزميات ، وهي عملية أو صيغة يتم من خلالها استرداد المعلومات المخزنة وترتيبها بطرق ذات معنى. لقد مرت هذه الخوارزميات بالعديد من التغييرات على مر السنين من أجل تحسين جودة نتائج البحث. على سبيل المثال ، تجري Google تعديلات على الخوارزمية كل يوم – بعض هذه التحديثات عبارة عن تعديلات ثانوية للجودة ، في حين أن البعض الآخر عبارة عن تحديثات خوارزمية أساسية / عريضة يتم نشرها لمعالجة مشكلة معينة ، مثل Penguin لمعالجة سبام الروابط الخلفية. تحقق من سجل تغيير خوارزميات Google للحصول على قائمة بكل تحديثات Google المؤكدة وغير المؤكدة التي ترجع إلى عام 2000.
لماذا تتغير الخوارزمية في كثير من الأحيان؟ هل تحاول Google فقط إبقائنا على أصابع أقدامنا؟ على الرغم من أن Google لا تكشف دائمًا عن تفاصيل حول سبب قيامها بما تقوم به ، إلا أننا نعلم أن هدف Google عند إجراء تعديلات الخوارزمية هو تحسين جودة البحث بشكل عام. لهذا السبب ، ردًا على أسئلة تحديث الخوارزمية ، ستجيب Google بشيء على غرار ما يلي: “نحن نجري تحديثات الجودة طوال الوقت.” يشير هذا إلى أنه إذا تعرض موقعك بعد تعديل الخوارزمية ، فقم بمقارنته بإرشادات الجودة من Google أو إرشادات Rater Quality Search ، فكلاهما مهمان للغاية فيما يتعلق بما تريده محركات البحث.
ماذا تريد محركات البحث؟
لطالما أرادت محركات البحث الحصول على نفس الشيء: تقديم إجابات مفيدة لأسئلة الباحث بالطريقة الأكثر فائدة. إذا كان هذا صحيحًا ، فلماذا يبدو أن تحسّين محركات البحث مختلف الآن عما كان عليه في السنوات الماضية؟
فكر في الأمر فيما يتعلق بتعلم شخص ما لغة جديدة.
في البداية ، فهمهم للغة بدائي للغاية . مع مرور الوقت ، يبدأ فهمهم في التعمق ، ويتعلمون دلالات – المعنى الكامن وراء اللغة والعلاقة بين الكلمات والعبارات. في النهاية ، مع الممارسة الكافية ، يعرف الطالب اللغة جيدًا بما يكفي لفهم الفوارق البسيطة ، وهو قادر على تقديم إجابات لأسئلة غامضة أو غير كاملة.
عندما كانت محركات البحث قد بدأت لتعلم لغتنا ، كان من السهل خداع هذا النظام باستخدام الحيل والتكتيكات التي تتعارض مع إرشادات الجودة. حشو الكلمات الرئيسية keyword stuffing ، على سبيل المثال. إذا كنت ترغب في التصدر بكلمة رئيسية معينة مثل “نكت مضحكة” ، يمكنك إضافة كلمات “نكت مضحكة” بضع مرات على صفحتك ، وجعلها غامقة وملونة ، على أمل تعزيز ترتيبك لهذا المصطلح:
مرحبا بكم في نكت مضحكة! نقول أطرف النكات في العالم. نكت مضحكة مرحة ومجنونة. نكتة مضحكة تنتظرك. اجلس واقراء النكات المضحكة لأن النكات المضحكة يمكن أن تجعلك سعيدًا وهي مسلية. بعض نكت مضحكة المفضلة.
هذا التكتيك سبب العديد من تجارب المستخدم السيئة bad user experience ، وبدلاً من الضحك على النكات المضحكة ، تعرض الناس للملل من خلال النصوص المزعجة التي يصعب قراءتها. ربما يكون قد نجح هذا الاسلوب في الماضي ، ولكن هذا ليس ما تريده محركات البحث.
أهمية الباك لينك او الروابط الخلفية في السيو SEO
عندما نتحدث عن الروابط ، يمكن أن نعني شيئين. الروابط الخلفية أو “inbound links” وهي روابط من مواقع أخرى تشير إلى موقع الويب الخاص بك ، في حين أن الروابط الداخلية هي روابط على موقعك الخاص تشير إلى صفحاتك الأخرى (على نفس الموقع).
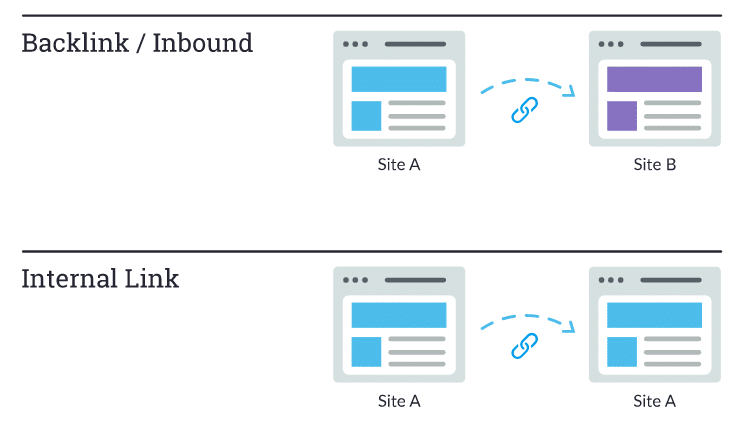
لعبت الروابط دورًا تاريخياً كبيرًا في تحسين محركات البحث SEO. في وقت مبكر جدًا ، احتاجت محركات البحث إلى مساعدة في معرفة عناوين URL الأكثر جدارة بالثقة من غيرها لمساعدتهم على تحديد كيفية ترتيب نتائج البحث. حساب عدد الروابط التي تشير إلى أي موقع معين ساعدهم على القيام بذلك.
تعمل الروابط الخلفية بشكل مشابه جدًا لإحالات WoM (Word-of-Mouth) الواقعية. لنأخذ كوفي شوب افتراضي ، اسمه Jenny’s Coffee ، على سبيل المثال:
- Referrals from others = good sign of authority
- مثال: أخبرك العديد من الأشخاص المختلفين أن قهوة Jenny هي الأفضل في المدينة
- Referrals from yourself = biased, so not a good sign of authority
- مثال: تدعي جيني نفسها أن قهوتها هي الأفضل في المدينة
- Referrals from irrelevant or low-quality sources = not a good sign of authority and could even get you flagged for spam
- على سبيل المثال: دفعت جيني لأشخاص لم يزروا القهمي الخاص بها أبداً لإخبار الآخرين بمدى جودته من اجل خداع الناس.
- No referrals = unclear authority
- على سبيل المثال: قد تكون قهوة Jenny جيدة ، لكنك لم تتمكن من العثور على أي شخص لديه رأي حولها لذلك انت غير متأكداً من جودة القهوة او المقهي عموماً.
هذا هو السبب في إنشاء PageRank. PageRank (جزء من خوارزمية Google الأساسية) هي خوارزمية تحليل الروابط التي سميت باسم أحد مؤسسي جوجل، Larry Page. يقوم PageRank بتقدير أهمية صفحة الويب عن طريق قياس جودة وكمية الروابط التي تشير إليها. الافتراض هو أنه كلما كانت صفحة الويب أكثر أهمية وجدارة بالثقة ، زادت الروابط التي حصلت عليها.
كلما كانت الروابط الخلفية الطبيعية لديك أكثر ومن مواقع ويب ذات ثقة عالية ، كلما كانت احتمالاتك للظهور في نتائج البحث الاولي أعلى.
دور المحتوى في تحسين محركات البحث SEO
لن تكون هناك فائدة من الروابط الخلفية إذا لم يضيف المحتوي للباحثين شيء ما. المحتوى أكثر من مجرد كلمات او عبارات مفتاحية. إنه أي شيء يُفترض أن يحتاجه او يبحث عنه الباحثون – الفيديو والصور والنصوص بالطبع. إذا كانت محركات البحث عبارة عن آلات للإجابة ، فإن المحتوى هو الوسيلة التي تقدم بها المحركات تلك الإجابات.
في أي وقت يقوم شخص ما بإجراء بحث ، هناك الآلاف من النتائج المحتملة ، فكيف تقرر محركات البحث الصفحات التي سيجدها الباحث قيمة؟ يتمثل جزء كبير من تحديد المكان الذي سيتم فيه تصنيف صفحتك في استعلام معين في مدى مطابقة المحتوى الموجود في صفحتك لهدف الاستعلام. بمعنى آخر ، هل تتطابق هذه الصفحة مع الكلمات التي تم البحث عنها وتساعد في إنجاز المهمة التي يحاول الباحث إنجازها؟
نظرًا لهذا التركيز على رضا المستخدم user satisfaction وإنجاز المهمة ، لا توجد معايير صارمة بشأن الطول الذي يجب أن يكون عليه المحتوى الخاص بك أو عدد المرات التي يجب أن يحتوي فيها على كلمة رئيسية أو ما تضعه في علامات الهيدر header tags. يمكن لجميع هؤلاء أن يلعبوا دورًا في جودة أداء الصفحة في البحث ، ولكن يجب أن يكون التركيز على المستخدمين الذين سيقرأون المحتوى.
اليوم ، مع وجود المئات أو حتى الآلاف من عوامل الترتيب ranking signals ، بقيت المراكز الثلاثة الأولى عادلة إلى حد ما: روابط إلى موقع الويب الخاص بك (والتي تعد بمثابة إشارات مصداقية من طرف ثالث) ، ومحتوى على الصفحة (محتوى عالي الجودة يستوفي نية الباحث) ، و RankBrain.
ما هو RankBrain؟
RankBrain هو مكون التعلم الآلي لخوارزمية Google الأساسية. التعلم الآلي عبارة عن برنامج كمبيوتر يواصل تحسين توقعاته بمرور الوقت من خلال الملاحظات الجديدة وبيانات التدريب. بمعنى آخر ، إنه يتعلم دائمًا ، ولأنه يتعلم دائمًا ، يجب أن تتحسن نتائج البحث باستمرار.
على سبيل المثال ، إذا لاحظت RankBrain عنوان URL أقل مرتبة يوفر نتيجة أفضل للمستخدمين من عناوين URL ذات التصنيف الأعلى ، فيمكنك المراهنة على أن RankBrain سيعدل تلك النتائج ، مما يؤدي إلى رفع النتيجة ذات الصلة إلى أعلى صفحة البحث وترتيب الصفحات الأقل ملاءمة كنتائج ثانوية.
مثل معظم الأشياء في محرك البحث ، لا نعرف بالضبط ما الذي يتكون منه RankBrain ، ولكن على ما يبدو ، كذلك لا يفهمه الأشخاص في Google.
ماذا يعني هذا بالنسبة للسيو؟
نظرًا لأن Google ستواصل الاستفادة من RankBrain للترويج للمحتوى الأكثر ملاءمةً ، فإننا نحتاج إلى التركيز على تحقيق نية الباحث searcher intent أكثر من أي وقت مضى. قدم أفضل المعلومات والخبرات الممكنة للباحثين الذين قد يتصفحوا موقعك ، وبهذا تكون قد اتخذت خطوة أولى كبيرة لتبلي بشكل جيد في عالم RankBrain.
مقاييس التفاعل: correlation, causation, أو كلاهما؟
مع مقاييس ترتيب Google ، غالبًا ما تكون مقاييس الارتباط هي part correlation وpart causation.
عندما نقول مقاييس التفاعل ، فإننا نعني البيانات التي تمثل كيفية تفاعل الباحثين مع موقعك من نتائج البحث. وهذا يشمل أشياء مثل:
- النقرات (الزيارات من البحث Clicks)
- الوقت على الصفحة (مقدار الوقت الذي يقضيه الزائر على الصفحة قبل مغادرته Time on page)
- معدل الارتداد (النسبة المئوية لجميع جلسات الموقع حيث شاهد المستخدمون صفحة واحدة فقط Bounce rate)
- Pogo-sticking (النقر على النتائج المجانية ثم العودة بسرعة إلى SERP لاختيار نتيجة أخرى)
لقد أوضحت العديد من الاختبارات ، بما في ذلك استبيان عوامل الترتيب الخاص بموز ، أن مقاييس التفاعل ترتبط مع النتائج الاعلي ، لكن العلاقة السببية causation كانت موضع نقاش قوي. هل مقاييس المشاركة الجيدة تشير فقط إلى المواقع ذات التصنيف العالي؟ أو هل تحتل المواقع مرتبة عالية لأنها تمتلك مقاييس ارتباط جيدة؟
ماذا قالت جوجل
رغم أنهم لم يستخدموا مطلقًا مصطلح “direct ranking signal” ، إلا أن Google كان واضحًا أنهم لم يستخدموا مطلقاً بيانات النقرات لتعديل SERP لاستفسارات معينة.
وفقًا لرئيس Google السابق لجودة البحث ، Udi Manber:
“الترتيب نفسه يتأثر ببيانات النقرات. إذا اكتشفنا أنه بالنسبة لاستعلام معين ، فإن 80٪ من الناس ينقرون على # 2 و 10٪ فقط على # 1 ، بعد فترة من الوقت ربما يكون رقم 2 هو الشخص الذي يريده الناس ، لذلك سنقوم بتبديله. “
هناك تعليق آخر من المهندس السابق لـ Google إدمون لاو يؤكد هذا:
“من الواضح تمامًا أن أي محرك بحث معقول سيستخدم بيانات النقرات على نتائجهم الخاصة لتعود إلى الترتيب لتحسين جودة نتائج البحث. غالبًا ما تكون الآليات الفعلية لكيفية استخدام بيانات النقرات ملكية ، لكن Google توضح أنه يستخدم بيانات النقرات مع براءات الاختراع الخاصة به على أنظمة مثل عناصر المحتوى المعدلة بحسب الرتبة. “
نظرًا لأن Google تحتاج إلى الحفاظ على جودة البحث وتحسينها ، فيبدو أنه من المحتم أن تكون مقاييس الارتباط أكثر من علاقة ارتباطية ، ولكن يبدو أن Google تفتقر إلى اعتبار مقاييس الارتباط “إشارة تصنيف” لأن هذه المقاييس تُستخدم لتحسين جودة البحث و ترتيب عناوين URL الفردية هو مجرد نتيجة ثانوية لذلك.
ما الاختبارات المؤكدة؟
أكدت العديد من الاختبارات أن Google ستعدل طلب SERP استجابة لمشاركة الباحث:
- نتج عن اختبار Rand Fishkin لعام 2014 نتيجة للانتقال إلى المرتبة الأولى بعد الحصول على حوالي 200 شخص للنقر على عنوان URL من SERP. ومن المثير للاهتمام ، أن تحسين التصنيف بدا معزولًا عن موقع الأشخاص الذين زاروا الرابط. ارتفع ترتيب المراتب في الولايات المتحدة ، حيث كان يوجد العديد من المشاركين ، بينما بقي أقل على الصفحة في Google Canada و Google Australia ، إلخ.
- يبدو أن مقارنة لاري كيم بالصفحات العليا ومتوسط وقت الإقامة قبل وبعد RankBrain تشير إلى أن مكون التعلم الآلي في خوارزمية Google يحدد موقع ترتيب الصفحات التي لا يقضيها الأشخاص في الكثير من الوقت.
- أظهر اختبار دارين شو تأثير سلوك المستخدم على نتائج البحث والخرائط المحلية أيضًا.
نظرًا لأن مقاييس ارتباط المستخدم تُستخدم بوضوح لضبط SERPs للجودة ، وترتيب التغييرات في المواضع كمنتج ثانوي ، فمن الآمن أن نقول إن مُحسّنات محرّكات البحث يجب تحسينها للمشاركة. لا يغيّر الارتباط الجودة الموضوعية لصفحة الويب الخاصة بك ، ولكن قيمتك للباحثين بالنسبة للنتائج الأخرى لهذا الاستعلام. لهذا السبب ، بعد عدم إجراء أي تغييرات على صفحتك أو روابطها الخلفية ، فقد تنخفض في التصنيف إذا كانت سلوكيات الباحثين تشير إلى أنهم يفضلون الصفحات الأخرى بشكل أفضل.
من حيث تصنيف صفحات الويب ، تعمل مقاييس الارتباط مثل مدقق الحقائق. تقوم العوامل الموضوعية مثل الروابط والمحتويات بترتيب الصفحة أولاً ، ثم تساعد مقاييس الارتباط Google في ضبط ما إذا كانت غير صحيحة.
تطور نتائج البحث
عندما كانت محركات البحث تفتقر إلى الكثير من التطور الذي نعاصره في وقتنا الحالي ، فإن مصطلح “10 روابط زرقاء” تم صياغته لوصف البنية المسطحة لـ SERP. في أي وقت يتم فيه إجراء بحث ، ستُرجع Google صفحة تحتوي على 10 نتائج عضوية ، كلٍ منها بنفس التنسيق.
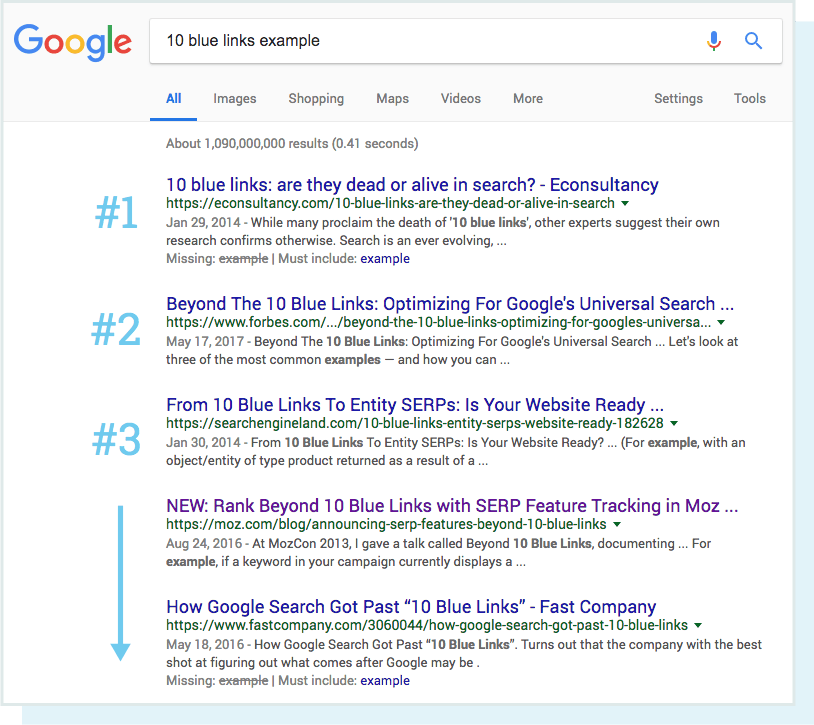
في هذا المشهد البحثي ، كانت النتيجة رقم 1 هي الكأس المقدس للسيو. ولكن بعد ذلك حدث شيء ما. بدأت Google في إضافة النتائج بتنسيقات جديدة على صفحات نتائج البحث الخاصة بها ، والتي تسمى ميزات SERP. تتضمن ميزات SERP بعض من الاتي:
- Paid ads
- Featured snippets
- People Also Ask
- Local map
- Knowledge panel
- Sitelinks
جوجل تضيف جديد في كل وقت. لقد جربوا أيضًا “SERPs ذات النتيجة الصفرية” ، وهي ظاهرة تم فيها عرض نتيجة واحدة فقط من Graph على SERP دون أية نتائج تحتها باستثناء خيار “عرض المزيد من النتائج”.
تسبب إضافة هذه الميزات بعض الذعر لسببين رئيسيين. الاول ، تسببت العديد من هذه الميزات في دفع النتائج المجانية لأسفل SERP. السبب الآخر هو أن عددًا أقل من الباحثين يقومون بالنقر فوق النتائج المجانية حيث يتم الرد على المزيد من الاستفسارات على SERP نفسه.
فلماذا تفعل جوجل هذا؟ كل شيء يعود إلى تجربة البحث. يشير سلوك المستخدم إلى أن بعض الاستعلامات يجاب عنها بشكل أفضل عن طريق تنسيقات المحتوي المختلفة. لاحظ كيف تتطابق الأنواع المختلفة لميزات SERP مع الأنواع المختلفة من نوايا الاستعلام.
| Possible SERP Feature Triggered | Query Intent |
| Featured snippet | Informational |
| Knowledge Graph / instant answer | Informational with one answer |
| map pack | local |
| shopping | transactional |
سنتحدث أكثر عن نية المستخدم في الفصل 3 ، ولكن في الوقت الحالي ، من المهم معرفة أنه يمكن تسليم الإجابات للباحثين في مجموعة واسعة من التنسيقات ، وكيف يمكن أن تؤثر بنية المحتوى الخاص بك على التنسيق الذي يظهر به في البحث.
Localized search
يحتوي محرك البحث مثل Google على فهرس خاص به لقوائم الأنشطة التجارية المحلية ، والتي ينشئ منها نتائج البحث المحلية.
إذا كنت تقوم بتحسين محلي للسيو من أجل شركة لها موقع فعلي يمكن للعملاء زيارته (على سبيل المثال: طبيب أسنان) أو لشركة أعمال تسافر لزيارة عملائها (على سبيل المثال: سباك) ، فتأكد من مطالبتك والتحقق منها وتحسينها عن طريق انشاء حساب Google My Business Listing.
عندما يتعلق الأمر بنتائج البحث localized search results ، تستخدم Google ثلاثة عوامل رئيسية لتحديد الترتيب:
- Relevance
- Distance
- Prominence
Relevance
الصلة او Relevance هي مدى مطابقة النشاط التجاريال محلي مع ما يبحث عنه الباحث. للتأكد من أن العمل يبذل كل ما في وسعه ليكون ذا صلة بالباحثين ، تأكد من أن معلومات النشاط التجاري تمتلئ بشكل كامل ودقيق.
Distance
تستخدم Google موقعك الجغرافي لتقديم نتائجك المحلية بشكل أفضل. تكون نتائج البحث المحلية حساسة للغاية للقرب ، والتي تشير إلى موقع الباحث و / أو الموقع المحدد في الاستعلام (إذا كان الباحث يتضمن واحدًا).
تكون نتائج البحث المجانية حساسة لموقع الباحث ، على الرغم من أنه نادرًا ما يكون واضحًا كما هو الحال في النتائج المحلية.
Prominence
مع بروزها كعامل ، تتطلع Google إلى مكافأة الشركات المعروفة في العالم الواقعي. بالإضافة إلى بروز نشاط تجاري غير متصل بالإنترنت ، تنظر Google أيضًا في بعض العوامل عبر الإنترنت لتحديد الترتيب المحلي ، مثل:
Reviews
عدد مراجعات Google التي تتلقاها شركة محلية ، وشعور هذه المراجعات ، يكون له تأثير ملحوظ على قدرتها على ترتيب النتائج المحلية.
Citations
يعد “الاقتباس التجاري” أو “قائمة النشاط التجاري” مرجعًا عبر الويب لنشاط تجاري محلي “NAP” (الاسم والعنوان ورقم الهاتف) على النظام الأساسي المترجم (Yelp و Acxiom و YP و Infogroup و Localeze وما إلى ذلك) .
تتأثر التصنيفات المحلية بعدد وتناسق الاستشهادات التجارية المحلية. تقوم Google بسحب البيانات من مجموعة واسعة من المصادر في تكوين مؤشر أعمالها المحلي بشكل مستمر. عندما تعثر Google على عدة إشارات متسقة إلى اسم الشركة وموقعها ورقم هاتفها ، فإنها تعزز “ثقة” Google في صحة هذه البيانات. يؤدي هذا إلى تمكين Google من إظهار النشاط التجاري بدرجة عالية من الثقة. تستخدم Google أيضًا معلومات من مصادر أخرى على الويب ، مثل الروابط والمقالات.
Organic ranking
تنطبق أفضل ممارسات SEO أيضًا على SEO المحلي ، نظرًا لأن Google تنظر أيضًا في موقع الويب في نتائج البحث المجانية عند تحديد التصنيف المحلي.
في الفصل التالي ، ستتعلم أفضل الممارسات On-Page التي ستساعد Google والمستخدمين على فهم المحتوى الخاص بك بشكل أفضل.
[مكافأة!] Local engagement
على الرغم من أن Google لم تدرجه كعامل تصنيف محلي ، إلا أن دور المشاركة سوف يزداد مع مرور الوقت. تواصل Google إثراء النتائج المحلية من خلال دمج بيانات العالم الحقيقي مثل الأوقات الشائعة للزيارة ومتوسط طول الزيارات …
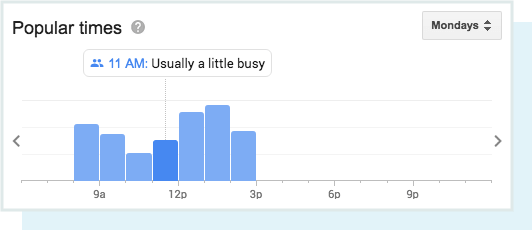
… وحتى يوفر للباحثين القدرة على طرح أسئلة عن العمل!

مما لا شك فيه الآن أكثر من أي وقت مضى ، تتأثر النتائج المحلية ببيانات العالم الحقيقي. هذه التفاعلية هي كيفية تفاعل الباحثين مع الشركات المحلية والاستجابة لها ، بدلاً من المعلومات الثابتة البحتة (يمكن التلاعب بها) مثل الروابط والاستشهادات.
نظرًا لأن Google ترغب في تقديم أفضل وأهم الشركات المحلية ذات الصلة للباحثين ، فمن المنطقي بالنسبة لهم استخدام مقاييس المشاركة في الوقت الحقيقي لتحديد الجودة والأهمية.
ليس عليك معرفة خصوصيات وعموميات خوارزمية Google (التي لا تزال غامضة!) ، ولكن الآن يجب أن تكون لديك معرفة أساسية بكيفية اكتشاف محرك البحث للمحتوى وتفسيره وتخزينه وترتيبه. مثقلاً نفسك بهذه المعلومات ، دعونا نتعرف على كيفية اختيار الكلمات الرئيسية التي سيستهدفها المحتوى في الفصل 3 (البحث عن الكلمات الرئيسية)!
المصدر: How Search Engines Work: Crawling, Indexing, and Ranking
طريقة عمل بحث Googleكيف تعمل محركات البحثكيف يعمل محرك بحث جوجل


موضوع رائع فقد علمني اشياء جديدة
تحياتى
شكرا لهذا الجهد الرائع.
لكن كيف يمكن ان نكيف الcrwlers foucse حول موضوع محدد